
写在前面
为了更好的理解下面提到的Linux下5种网络IO的概念,我们还是有必要先理清几个概念。
1.程序空间与内核空间
在Linux中,对于一次读取IO的操作,数据并不会直接拷贝到程序的程序缓冲区。它首先会被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的缓冲区。p.s: 最后一句话非常重要,重复一遍。
Waiting for the data to be ready(等待数据到达内核缓冲区)
Copying the data from the kernel to the process(从内核缓冲区拷贝数据到程序缓冲区)
2.阻塞与非阻塞
阻塞就是说我们某一个请求不能立即得到返回应答,否则就可以理解为非阻塞。
3.同步IO与异步IO
这里先直接引用Stevens(POSIX)的定义:
对于同步与异步,我们可以用一个简单的生活场景来描述。当我们排队在实体店买东西可以视作同步,而网购则可以视作异步。实体店排队这种同步情形显然是非常的浪费时间,等待的这段时间我们被阻塞住了不能干其他的事情,而网购只要我们提交一下订单之后其他什么都不用管了,商品到了,快递员给我们发送一个信号(打电话)我们直接到门口去拿,等待的这段时间我们可以用来撸代码。
p.s: 等你阅读完文章的后面部分,回过头来看异步其实就是将等待的这段时间去处理IO操作,把CPU(我们的大脑)让出来做其他更有价值的事情(撸代码),而不是像同步那样去傻傻地排队。更加详细准确的定义可以在阅读完本文后面部分后参考维基百科。
4.文件描述符
在Linux下面一切皆文件,文件描述符(file descriptor)是内核为文件所创建的索引,所有I/O操作都通过调用文件描述符(索引)来执行,包括下面我们要提到的socket。Linux刚启动的时候会自动设置0是标准输入,1是标准输出,2是标准错误。
5种网络IO模型
大家还是应该多结合Stevens的图片来理解,不要只看我枯燥的文字总结。
1.blocking IO(阻塞IO)
blocking IO
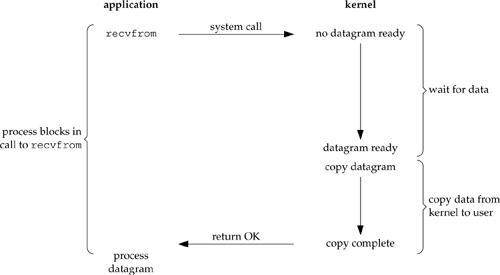
如图所示,进程调用一个recvfrom请求,但是它不能立刻收到回复,直到数据返回,然后将数据从内核空间复制到程序空间。这里我们再次回顾开篇提到的两个过程:
Waiting for the data to be ready(等待数据到达内核缓冲区)
Copying the data from the kernel to the process(从内核缓冲区拷贝数据到程序缓冲区)
注意到没有,在上面这两个过程中,进程都处于blocked(阻塞)状态,在等待数据返回的过程中不能空闲出来干其他的事情。
2.nonblocking IO(非阻塞IO)
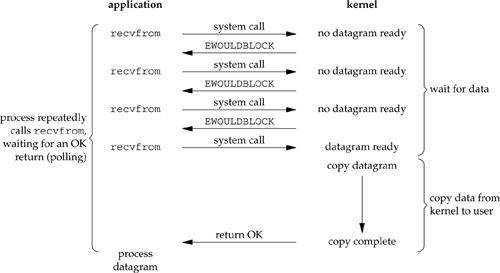
当我们设置一个socket为nonblocking(非阻塞),相当于告诉内核当我们请求的IO操作不能立即得到返回结果,不要把进程设置为sleep状态,而是返回一个错误信息(下图中的EWOULDBLOCK)。
nonblocking IO
我们来分析一下图片中的整个流程。前三次我们调用recvfrom请求,但是并没有数据返回,所以内核只能返回一个错误信息(EWOULDBLOCK)。但是当我们第四次调用recvfrom,数据已经准备好了,然后将它从内核空间复制到程序空间。
在非阻塞状态下,我们的过程一(wait for data)并不是完全的阻塞的,但是过程二(copy data from kernel to user)依然处于一个阻塞状态。
3.IO multiplexing(IO复用)
IO复用的好处是...
点击查看剩余70%













 {{collectdata}}
{{collectdata}}






网友评论0